High Availability Architecture as a Goal of Best Practices
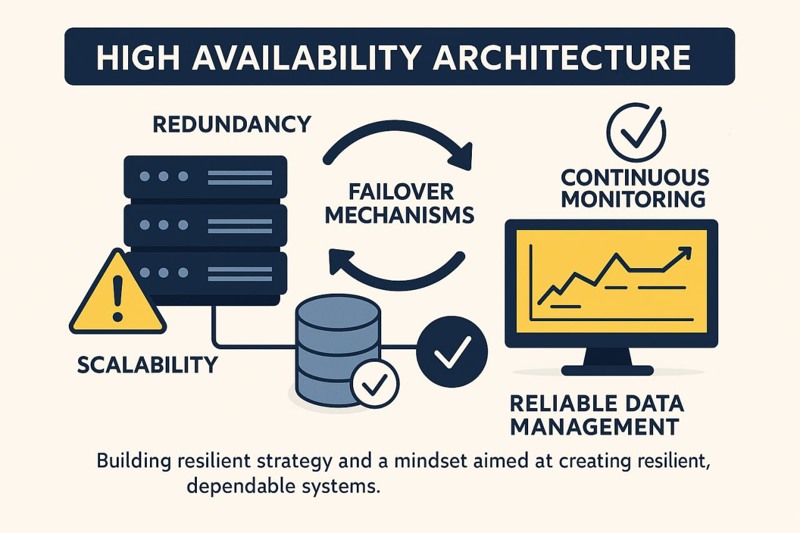
High availability architecture helps systems stay operational when failures occur. By combining redundancy, failover, scalability, and strong monitoring, teams can reduce downtime and build more resilient services.
High availability architecture is one of the clearest examples of how best practices become practical business value. When systems remain available during failures, organizations protect user trust, reduce operational stress, and avoid costly downtime. In modern software environments, availability is not only a technical target but also a quality standard that shapes how systems are designed from the beginning.
A reliable platform is not built on the assumption that nothing will fail. It is built on the expectation that failures will happen and that the system must continue operating anyway. Hardware can break, traffic can spike, dependencies can become slow, and human error can introduce risk. High availability turns those realities into design inputs instead of unexpected disasters.
Why high availability matters
Downtime affects more than infrastructure. It affects customer confidence, team productivity, revenue, and the reputation of the product itself. Even short interruptions can create a visible loss of trust when users depend on a service for daily work or critical tasks. That is why high availability is often treated as a strategic requirement, not just a technical improvement.
High availability also creates operational stability. Teams that work with resilient systems spend less time reacting to incidents and more time improving the platform. Instead of constantly recovering from preventable failures, they can focus on optimization, delivery, and long-term reliability.
Eliminating single points of failure
One of the first principles of high availability is removing single points of failure. If one component can bring down the entire system, the architecture is fragile. A single application server, one database instance, or one dependent network path can all become critical weaknesses when no alternative exists.
The usual answer is redundancy. Multiple application instances behind a load balancer, replicated services, and infrastructure distributed across zones or regions all reduce the chance that one failure becomes a full outage. Redundancy may seem excessive in calm periods, but it becomes essential the moment a single critical component stops responding.
Failover and redundancy
Failover is the mechanism that allows a healthy component to take over when another component becomes unavailable. This can apply to compute instances, databases, caches, or even network routes. The goal is simple: users should experience little or no disruption when part of the system fails.
Designing failover well requires planning, testing, and operational discipline. It is not enough to have backup systems if switching to them is slow, manual, or unreliable. True resilience comes from predictable recovery paths that are tested before they are needed in production.
Scalability as part of availability
Availability and scalability are closely connected. Systems often fail not because of a defect, but because demand exceeds capacity. A traffic spike, a heavy background job, or an unexpected burst of new users can overwhelm an underprepared service just as effectively as a hardware outage.
That is why load balancing and horizontal scaling are central to high availability. Distributing traffic across multiple instances helps prevent overload while making it easier to replace unhealthy nodes without interrupting the whole system. Capacity planning also plays an important role, because resilience depends on having enough headroom to absorb abnormal conditions.
Data resilience and backups
Service uptime is only part of the equation. The data behind the system must also remain available, durable, and recoverable. Replication helps keep data accessible across multiple nodes, while backups provide protection against corruption, accidental deletion, and catastrophic failures.
A strong availability strategy includes thinking carefully about recovery objectives, restore procedures, and consistency trade-offs. Teams should know how quickly they can restore data, how much data they can afford to lose, and what systems must be prioritized during recovery. Without this planning, a service may appear available while the underlying data remains vulnerable.
Monitoring and operational readiness
High availability depends on visibility. Monitoring, logging, tracing, and alerting help teams detect problems early and respond before users experience widespread disruption. Good observability turns hidden degradation into actionable information.
Operational readiness also matters. Runbooks, incident reviews, on-call processes, and failure simulations all strengthen the system around the architecture itself. Teams that regularly practice recovery are much better prepared when a real incident occurs. In that sense, high availability is as much an operational habit as it is a technical pattern.
Conclusion
High availability architecture is not about pretending failures can be eliminated. It is about designing systems that continue to serve users when failures inevitably happen. By removing single points of failure, building redundancy, enabling failover, planning for scale, protecting data, and improving observability, teams create services that are both more stable and more trustworthy.
Best practices become meaningful when they improve real outcomes. High availability does exactly that. It transforms infrastructure from a fragile dependency into a resilient foundation that supports growth, reliability, and long-term confidence.